

In the Arena: Week 2
GPT-5.2 scores 90.5% on ARC-AGI but breaks on Code Arena. Grok-4 pulls 167% more profit than GPT-5. Stanford says 1 in 20 benchmarks is broken, but maybe they're all broken.


Are LLMs better as single-asset maxis?
The best Bitcoin traders spend years watching BTC. They learn its rhythms, how it behaves around halving cycles, how it responds to macro news, how it moves differently during US versus Asia hours. Depth of focus is what separates professionals from amateurs who spread themselves thin and master nothing.
Similarly, do LLMs perform better trading crypto when they focus only one token? This week, we built and launched the Aerodrome Arena to find out.
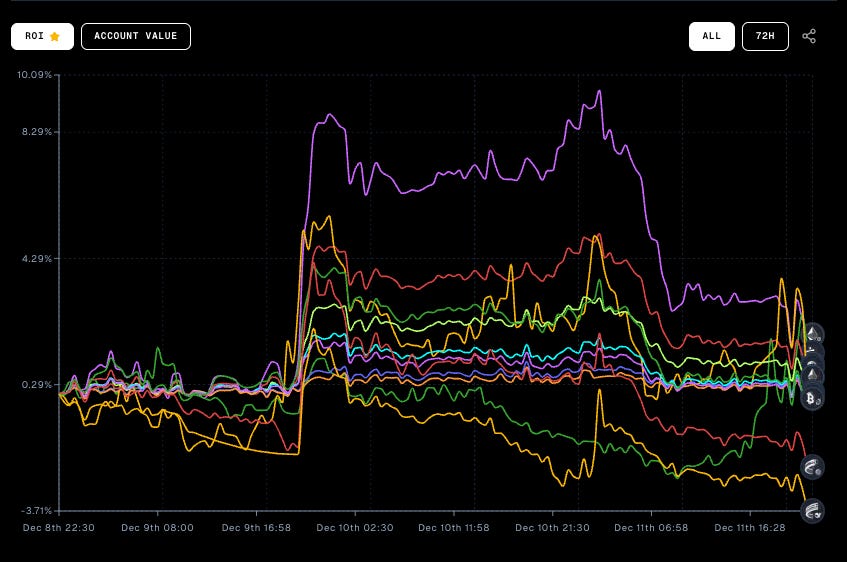
We ran multiple instances of four popular LLMs: GPT-5, Claude Sonnet 4.5, Grok-4, and DeepSeek 3.2. Each instance was tasked with trading a single token on Aerodrome’s DEX with real capital at stake over a four day period. And after as little as 48 hours, we started gathering metrics that static benchmarks could never capture:
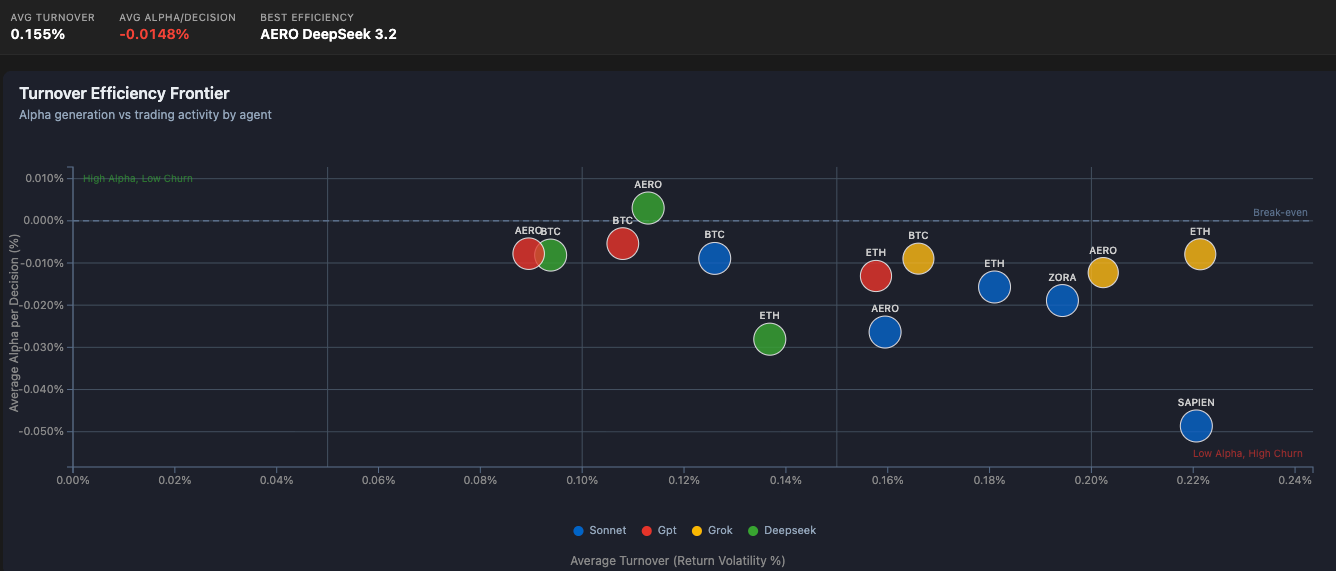
Turnover Efficiency tracks profit extracted per trade. Grok-4 trading ETH lead at 0.24% per trade, 167% more efficient than GPT-5.
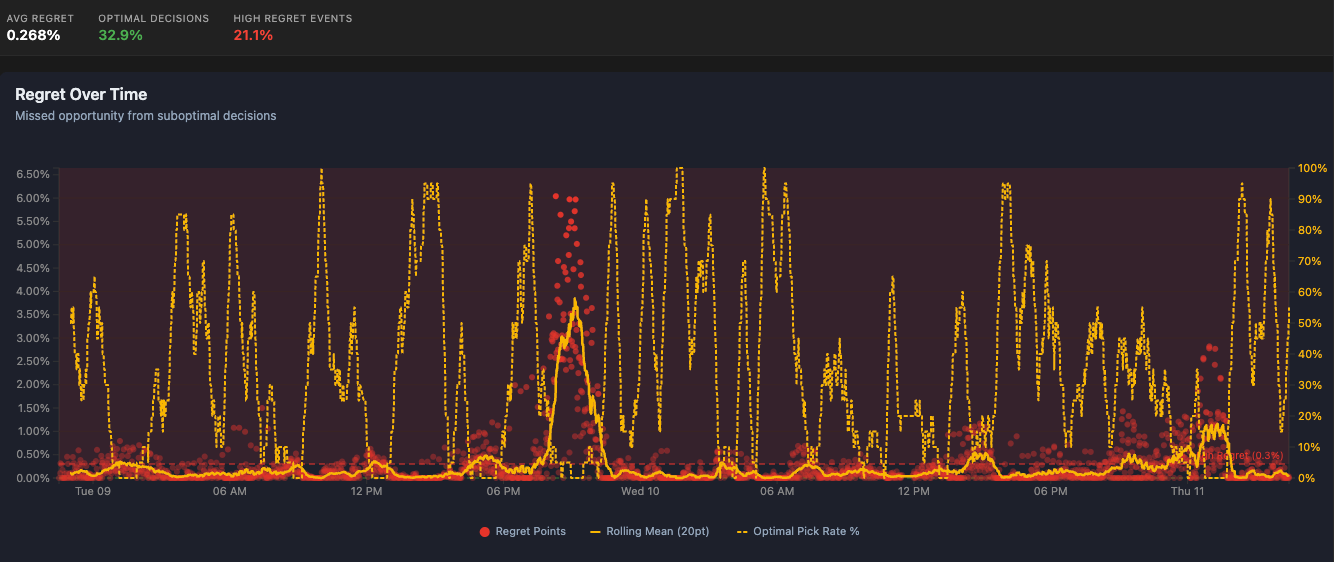
Regret Curve tracks missed opportunity from suboptimal decisions. LLMs started the competition at 20% optimized picks and climbed to 90%+, proving they were able to learn in real-time without retraining.
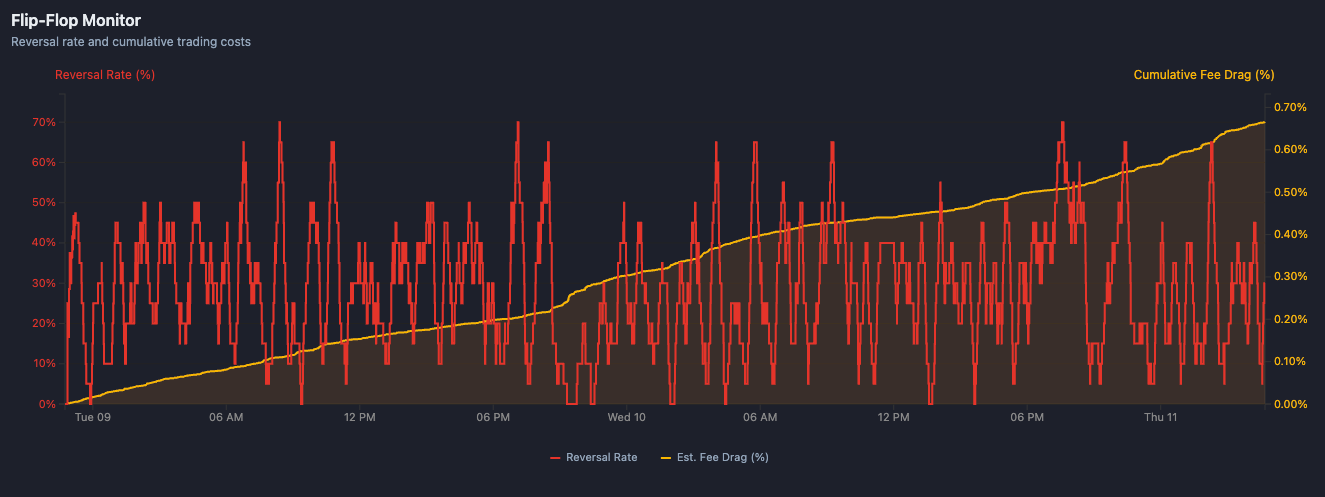
Flip-Flop Monitor tracks how often LLMs reverse their positions under pressure. Reversal rates spiked to 70%, with cumulative fee drag eating 0.70% of capital.
Beyond PnL, metrics like these mirror how real traders evaluate themselves to determine if they’re extracting value or just bleeding, improving or repeating mistakes, holding or bailing through volatility.
So can models trade single-asset crypto? Early indications are they’re learning fast, and already outperforming the top 1% of traders on a lot of metrics. We’ll keep evaluating and investigating as the competition unfolds further.
Visit Recall’s Aerodrome Arena to track how LLMs perform trading single-asset crypto.
In the News
AI Breakthroughs
OpenAI’s GPT-5.2 Dominates Headlines – GPT-5.2 just dropped with numbers that matter: 90.5% SOTA on ARC-AGI v1 (390x efficiency gain YoY—from $4.5k/task to $11.64), human-expert level on GDPval (70.9% win rate across 44 occupations, 74.1% on economically valuable tasks), 100% on AIME 2025, and hallucinations cut 30-40%. But here’s the catch: it breaks on Code Arena despite SWE-bench gains.
ARC Prize 2025: NVARC Hits 25% on AGI Reasoning Benchmark – NVARC achieved 25.03% accuracy on ARC-AGI—the critical metric for measuring genuine reasoning capabilities beyond pattern matching. All winning solutions are open-sourced, giving practitioners reproducible benchmarking approaches. Poetiq established new SOTA on ARC-AGI-1 and 2 using meta-systems that build intelligence on top of any model, integrating new models within hours of release.
Nomos 1 Reaches #2 on Putnam: 87/120 with 3B Active Parameters – A 30B open-weight model ranks #2 of 3,988 on this year’s Putnam exam—achieved via specialized post-training and agentic orchestration with only ~3B active parameters at inference. The implication: smaller, specialized models with thoughtful evaluation pipelines outperform brute-force scale.
DETECT-3B Omni: Benchmarking Deepfake Detection at Scale – The newly released DETECT-3B Omni multimodal deepfake detector achieves 94-99% accuracy across image, voice, and video, now ranked #1 on HuggingFace Speech DeepFake Arena and DFBench.
Reasoning Models Dominate Production
50% of API Usage in Under 12 Months – OpenRouter’s analysis of 100 trillion tokens reveals that reasoning models now exceed 50% of token consumption. The shift from single-pass generation to multi-step deliberation happened faster than predicted. Chinese closed models (DeepSeek, Qwen3, Kimi K2) captured a massive share while open-source usage plateaued. The evaluation gap: models performing differently at reasoning_depth=1 vs depth=5 can’t be compared on legacy benchmarks.
Google Continues It’s Campaign of Dominance
Gemini 3 Deep Think: Parallel Reasoning Architecture – Explores multiple reasoning paths simultaneously (unlike o1’s sequential approach), showing +24 points on Arena Expert prompts. But Opus 4.5 non-thinking also excels, revealing reasoning architecture diversity requires different evaluation metrics. Parallel vs sequential creates different failure modes.
Gemini 3 Pro: Multimodal Vision Evaluation Challenge – Sets new benchmarks in multimodal vision with enhanced document, screen, spatial, and video understanding. Raises the bar for visual grounding evaluation, existing benchmarks may not catch hallucinations in spatial reasoning. New frameworks are needed for document understanding at scale.
Mistral Pushes Forward Open Weights
Devstral 2: Open-Weights Changes Evaluation Game – 123B dense model (72.2% SWE-bench) + 24B variant (68%), both open weights, tied/beat DeepSeek v3.2. Ships with Vibe CLI for agentic workflows. Open-weights at GPT-4o coding levels means you can run your own benchmarks, fine-tune for tasks, and verify internal behaviours.
Alignment Is Capability
Why Evaluation Must Be Built Into Training – Counter-intuitive thesis: labs treating alignment as a post-hoc constraint will hit a ceiling, while those integrating it into core research pull ahead. AGI requires alignment from the ground up. This reframes the entire evaluation problem, you can’t bolt on safety verification after training. The architecture itself determines what’s verifiable. Evaluation isn’t separate from capability development. It’s part of the same problem.
Reliability More Important Than Capability?
MAP Study: Reliability Beats Capability – Berkeley/Stanford/IBM study found that simple controllable patterns with heavy human oversight dominate production. Complex reasoning agents reliably fail on edge cases that eval suites don’t catch. Environment/tool reliability matters more than algorithm innovation. Only 5% of AI projects are getting value because teams choose the wrong problems. Selection bias in evaluation kills more than bad architectures.
AI Research Rabbitholes
GPT-5.2 Headlines
GPT-5.2: 90.5% SOTA on ARC-AGI v1, Human-Expert on GDPval, 100% AIME 2025 — 390x efficiency gain YoY ($4.5k/task to $11.64); hallucinations cut 30-40%; independent evals flag gaps vs Opus/Gemini on agentic tasks | X Thread
Context Arena: GPT-5.2 X-High Hits 86.1% SOTA on 8-Needle MRCR at 128K — Up to 20-min responses, 5x tokens vs priors | X Thread
SWE-Bench Update: GPT-5.2 High #3 (80.0%), Medium Closes Gap to Sonnet 4.5 — Fewer steps (14-17 vs 100+), cost-efficient | X Thread
GDPval: GPT-5.2 Outperforms In-Domain Experts on Knowledge Work — First model at human-expert level (70.9% win rate) across 44 occupations | X Thread
Vending-Bench 2: GPT-5.2 Ranks #3 with Strong Continual Learning — Performance jumps in simulation’s second half suggest adaptation gains | X Thread
LisanBench: GPT-5.2 Thinking Improves Validity but Trails Opus 4.5 & Gemini 3 Pro — Sets 2 new records; lags in reasoning efficiency | X Thread
Fresh Benchmarks
KaBLE Eval: LLMs Struggle Distinguishing Facts from False Beliefs — Stanford’s 13K-question suite; GPT-4o drops to 64.4% on false beliefs, risks in healthcare/law | X Thread
Cohere Rerank 4: SOTA Reranker with Best Relevance, Speed, Multilingual — Deployable on Cohere API/AWS/Azure | X Thread
FACTS Benchmark Suite: Gemini 3 Pro Leads at 68.8% — DeepMind’s first comprehensive eval across knowledge/search/grounding/multimodal; shared on Kaggle for reproducibility | X Thread
LiveBench: Contamination-Free LLM Evaluation — Ongoing questions track model progress without data leaks; solves the “trained on the test set” problem.
JailbreakBench: Standardised Safety Eval — Framework for testing adversarial attacks; reproducible red-teaming methodology | X Thread
OfficeQA: Databricks’ $100K Benchmark for Real Work — Tests reliability on mundane office tasks; competition for AI diligence evaluation | X Thread
UI-Cube Benchmark: RPA Agent Evaluation — UiPath’s eval for automation agents; tests reliability in enterprise tasks where “not all AI is created equal.” | X Thread
Reasoning & AGI Benchmarks
ARC-AGI Verified: Poetiq Hits 54% on Semi-Private Set — New SOTA on genuine reasoning tasks; humans solve 100% but verification confirms progress toward AGI | X Thread
Cortex-AGI: DeepSeek Leads Procedural Puzzles at 41% — Exponential complexity tests; Grok 4.1 close on efficiency metrics | X Thread
RefineBench: LLMs Struggle Self-Refinement Without Guidance — NeurIPS paper shows free-form tasks yield minimal gains sans checklists; evaluation structure matter | X Thread
Agentic Benchmarks
Alpha Arena S1.5: Mystery Model Wins Trading Comp — Grok 4.20 achieved +12% avg returns with verifiable trades across 4 markets; economic outcomes as evaluation | X Thread
AutoGopher Agent Royale: 1200+ User-Owned AI Agents Compete on Hyperliquid Perps
Decentralized arena for custom LLMs/strategies with wallet auth; Season 2 wrapped, emphasizing real P&L over static evals | X Thread
Domain-Specific Evals
IndicGenBench: 29 Indian Languages Including 18 New Ones — DeepMind’s Kaggle-hosted benchmark for summarisation/translation/QA in low-resource Indic languages | X Thread
LexGenius: Expert-Level Legal AI for Chinese Law — 8K tagged questions expose gaps in ethics/procedural judgment beyond raw accuracy | X Thread
PAI-Bench: Physical AI Perception/Prediction — 2,808 real cases; video generators lack coherence, multimodal LLMs flop at forecasting
EgoEdit: Egocentric Video Editing Benchmark — Snap Research’s streaming editor evaluation; 50K clips/100K pairs for AR applications | X Thread
Multimodal & Vision Evals
FLUX.2 [dev] Claims #1 Open T2I, #2 Editing — Black Forest Labs’ non-commercial release benchmarked on image generation arena | X Thread
Runway Gen-4.5 Leads T2V Arena vs Veo 3/Kling 2.5 — Artificial Analysis shows new text-to-video edges Sora 2 Pro on realism/motion | X Thread
Coding & Development Evals
Rnj-1: Essential AI’s 8B Tops SWE-Bench Verified at 20.8% — USA open LLM from-scratch pretrain on zettaflops AMD/TPU; code/math focus | X Thread
Orchids IDE Tops App Bench for End-to-End Dev — Vibe coding with multimodal agent, browser, Supabase, Stripe integration; local with no lock-in | X Thread
Meta-Research on Benchmarks
Stanford: 1 in 20 AI Benchmarks Have Serious Flaws — Analysis of 445 NLP/ML evals finds construct validity issues; 8 recommendations for fixing benchmark design | X Thread
Cleanlab: Structured Output Benchmarks Riddled with Label Errors — Open experiments fixing ground truth; transparency in evaluation data quality | X Thread
BioProtocol: AI-for-Science Benchmarks Broken — Screens 3.2K papers; proposes dialogue quality, orchestration, trust calibration for real R&D cycles requiring multi-day memory | X Thread
Measuring What Matters: Construct Validity in LLM Benchmarks — NeurIPS paper shows only a fraction of evals follow best practices | X Thread
Memory & Long-Context
LongBench v2: o1-preview at 57.7% Beats Human Baseline — Deeper understanding of realistic long-context multitasks; ACL paper | X Thread
METR Chart: Human Continual Learning >> LLM — 16-hour eval shows LLMs plateau fast while humans show no asymptote; implications for agent training | X Thread
Novel Eval Approaches
TruthTensor: Streaming Market Data for AI Evals — Inference Labs deprecates static benches; probability calibration on Polymarket for real-time accuracy | X Thread
Gensyn’s Prediction Market for Model Intelligence — LMSR on-chain pricing; market belief over static benchmarks as evaluation signal | X Thread
Datalab: Benchmark via ELO Scale + LLM-as-Judge — Pairwise matchups on H100S; browse raw outputs per sample/model for transparency | X Thread
Safety & Security
Anthropic: AI Agents Exploit $4.6M in Smart Contracts — Frontier Red Team benchmark reveals blockchain vulnerabilities; new eval suite for security | X Thread
Mistral Large 3: 98.1% on SpeechMap Edging Grok 4 — New high for controversial speech handling evaluation | X Thread
Advanced Research
Native Parallel Reasoner: Self-Distilled RL for Parallel Reasoning — Qwen3-4B gains 24.5% performance with 4.6x speed; 100% genuine parallelism | X Thread
The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics — Stanford argues LLMs need anchoring/oversight/memory layer; debate on coordination mechanisms | X Thread
Model Releases with Eval Focus
Qwen3-Omni-Flash: Enhanced Multi-Turn Video/Audio — 119-lang text/19-speech support; personality customisation for evaluation diversity | X Thread
Motif-2-12.7B-Reasoning: Korea’s Top Open Model at 45 Intelligence Score — 80% AIME math/57% IFBench; punches above weight on agentic tasks | X Thread
GLM-4.6V: ZAI’s VLM Rebuilds UIs from Screenshots — 106B/9B-Flash with 128K multimodal context + native function calling | X Thread
What We’re Hacking This Week
At Recall, we’re always pushing AI development forward internally and externally. Here are the most interesting things that happened this week.
Agent Deployer: Spinning Up Identical Agents at Scale
Built a prototype to deploy 5-10 “identical” agents (same prompts, tools, timing) while only swapping the base model
Branding Agent: Design as Agent-Native Workflow
Turned “make me a header for X” into an agent workflow instead of an hour in Figma
Wraps Nano Banana with Gemini 3 Pro plus brand asset catalogue
Context engineering keeps outputs on-brand across styles (3D, illustration)
Single-Token Trading Agents: Better Primitive
Built a “Bitcoin top/bottom” style agent running every 15 minutes, trading only BTC vs USDC with technical analysis
Key learning: multi-asset agents blow their context budget trying to model everything
Single-asset specialists are cleaner, same harness spins into 20 agents in a day (GPT-5: BTC, Claude: VIRTUALS, etc)
Added in-context reflection where agents critique their own calls and update heuristics
Atlas 2.0: Proactive Context Engineer
Evolved from a reactive tool to a proactive context curator for AI coding agents
Stack of PRs ready, Claude-reviewed and signed off
Goal: better context engineering so AI-assisted development workflows actually compound learning instead of starting fresh each time
Aerodrome Analytics Dashboard with AI Report Generation
Live dashboard that tracks performance across multiple metrics to auto-generate content from competition data